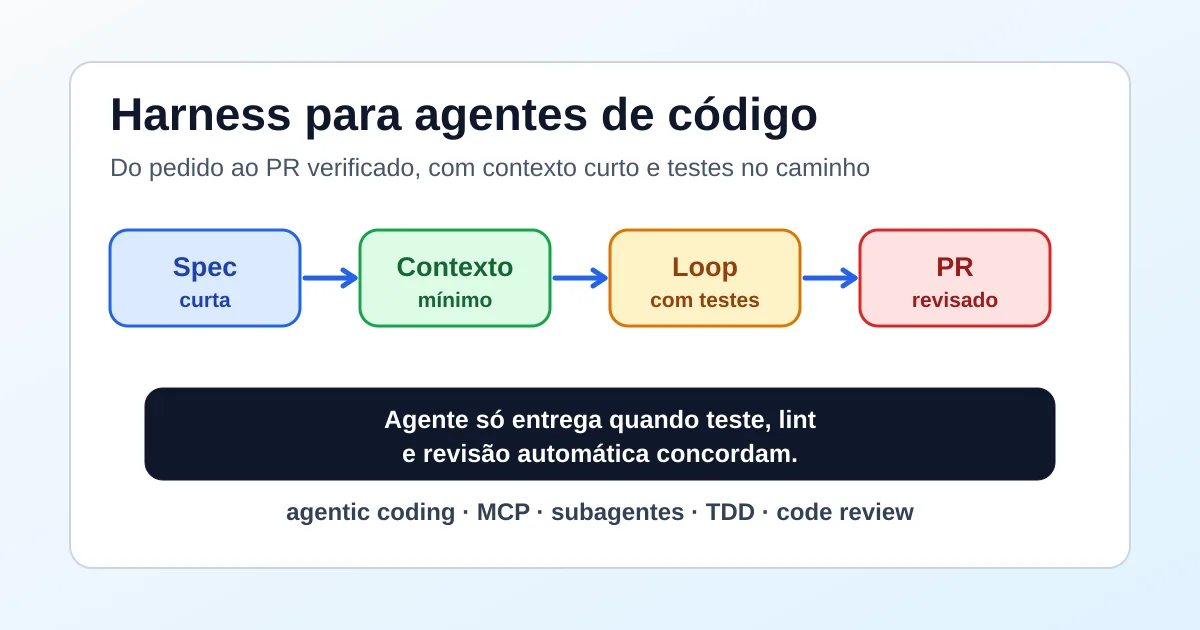
A code agent harness keeps Claude Code, Codex or another coding agent from turning a good request into a broken pull request. It defines the input, context, tools, tests, review and exit criteria. The short answer: the agent opens a PR only after technical evidence passes.
In 2025, the Stack Overflow Developer Survey 2025, AI section, reported that 84% of respondents use or plan to use AI in the development process, up from 76% the year before (Stack Overflow, Developer Survey 2025 AI, accessed 2026-06-30). That explains the urgency. The practice still needs to move beyond loose prompts.
A code agent harness is a small set of rules and checks around the agent. It does not replace architecture, human review or CI. It reduces ambiguity so the agent behaves like a verifiable executor, not like an imaginary teammate with confident prose.
This article starts from a practical observation: teams do not suffer only because AI writes wrong code. They suffer because the error arrives late, buried inside a large diff, without a clear test and with too much context to review quickly.
Versions of this article: Português and Español. For authorship context, see the about page. For editorial contact, use the contact page.
TL;DR
- If 84% of developers use or plan to use AI, the edge is not using an agent. It is verifying output.
- A good harness starts with a short spec, minimal context, reproducible tests and a PR rule.
- Subagents and MCP help when they reduce noise; when they expand surface area without proof, they hurt.

What is a code agent harness?
In 2025, the Stack Overflow Developer Survey 2025, AI section, reported 84% AI use or planned use in development (Stack Overflow, Developer Survey 2025 AI, accessed 2026-06-30). A harness is the operational answer to that volume: it turns an agent run into a flow with auditable input, tools and output.
Think in five blocks. First comes the spec: a short description of expected behavior and what is out of scope. Then comes context: files, contracts, logs and prior decisions that actually matter. Next comes agent execution, with permissions that match the risk of the task.
The fourth block is verification. This is where unit tests, integration tests, lint, typecheck, local migrations or repository-specific quality commands belong. The fifth block is the decision: open a PR, return to the loop or ask for human review before touching more code.
In short, a code agent harness is a boundary between generation and delivery. Stack Overflow reported 84% AI use or planned use in development in 2025 (Stack Overflow, Developer Survey 2025 AI, accessed 2026-06-30), but adoption does not equal quality. The harness requires each change to pass through a short spec, explicit context, reproducible commands and a PR decision that another person can audit later.
When should you use subagents in agentic coding?
In 2025, the same survey reported that 51% of professional developers use AI tools daily (Stack Overflow, Developer Survey 2025 AI, accessed 2026-06-30). Subagents make sense when that daily use starts polluting the main conversation with logs, searches, long files or parallel reviews.
Claude Code documentation describes subagents as specialized assistants running in their own context windows, with specific prompts, tools and permissions (Anthropic, Create custom subagents, accessed 2026-06-30). The technical benefit is simple: the main conversation receives a synthesis, not a dump.

Use a subagent for codebase exploration, log reading, diff review and test checks. Do not use a subagent to multiply blind attempts. If three agents write code at the same time without a shared spec, you gain apparent concurrency and lose traceability.
In long flows, the real savings come from not loading everything into the same window. When the agent needs to cross large repositories, a resource such as RemoteCode for extending Claude Code and Codex in agentic flows can help work go further with less wasted context, as long as the harness still decides what passes.
How should you choose context before the agent writes code?
In 2025, Stack Overflow reported 47.1% daily AI use among all respondents and 17.7% weekly use (Stack Overflow, Developer Survey 2025 AI, accessed 2026-06-30). With frequent usage, context becomes the bottleneck: sending the whole repository feels safe, but often creates noise.
Start with a short list. Include the issue or spec, likely files, API contracts, nearby tests, validation commands and architectural decisions that are not obvious in code. Exclude irrelevant history, repeated logs, generated files and old documentation unrelated to the change.
A useful move is to ask the agent for a context plan before implementation. It should say which files it will read and why. If the list is too broad, reduce it. If a critical contract is missing, add it before code. Context engineering is triage, not accumulation.
Where does MCP fit without creating risk?
In 2025, 13.7% of Stack Overflow respondents said they use AI monthly or infrequently, while 5.3% did not use it yet but planned to soon (Stack Overflow, Developer Survey 2025 AI, accessed 2026-06-30). For teams in transition, MCP should enter by need, not fashion.
The Model Context Protocol is an open standard for connecting AI applications to external systems, such as files, databases, tools and workflows (Model Context Protocol, What is MCP?, accessed 2026-06-30). In Claude Code, MCP can connect tools, databases, APIs, issues and observability dashboards (Anthropic, Connect Claude Code to tools via MCP, accessed 2026-06-30).

Use MCP when the agent must fetch an issue, query a test database, read a Sentry error or open a pull request. Do not connect tools just because they exist. Each server increases permission surface, prompt injection risk and cognitive cost.
How do you build the spec, TDD and CI loop?
In 2025, AI use or planned use in development reached 84%, up from 76% the year before (Stack Overflow, Developer Survey 2025 AI, accessed 2026-06-30). That changes the question: not whether the agent writes code, but which loop stops it from writing without proof.
The minimum loop has six steps:
- Write a one-page-or-less spec with expected behavior and out of scope.
- Ask the agent for a file and command plan before editing.
- Create or adjust the test first when the change allows it.
- Make the smallest patch that satisfies the spec.
- Run tests, lint and typecheck in a clean environment.
- Generate an automated review with blockers and residual risks.
This sequence works well with TDD because the agent receives a concrete boundary. If the test fails before and passes after, the conversation changes. The agent stops arguing that the change “seems right” and starts demonstrating behavior. For backend work, this applies to HTTP contracts, queues, migrations, idempotency and observability.
Claude Code also offers hooks for running commands at lifecycle points, such as after edits or before sensitive commands (Anthropic, Automate actions with hooks, accessed 2026-06-30). Use hooks for formatting, protected-file blocking and deterministic validations. Judgment still belongs in review.
How should you review a PR generated by AI?
In 2025, 16.2% of Stack Overflow respondents said they do not use AI and do not plan to use it in development (Stack Overflow, Developer Survey 2025 AI, accessed 2026-06-30). That group is a useful reminder: trust is not mandatory. An AI-generated PR has to earn it.
Start with the spec contract. Does the diff solve exactly what was requested? Does the test prove the main case? Is there unrelated change hidden in another file? Did the agent cite external behavior or tool output without a link? Did a migration, permission or environment variable stay implicit?
Ask for an automated review before the human reviewer. It should list blockers, risks and commands run. Do not accept a review that only praises the change. A good automated reviewer looks for contract failures, edge cases, security regression, performance risk and mismatch between code and test.
The best maturity signal is not the agent opening a PR alone. It is the agent knowing when it should not open one. If the source was not verified, the test does not cover the flow or the diff grew beyond the spec, the right result is to return to the loop.
Checklist before letting the agent open the PR
In 2025, Stack Overflow showed that 84% of respondents already use or plan to use AI in development, but that does not validate every automation (Stack Overflow, Developer Survey 2025 AI, accessed 2026-06-30). The final checklist should be smaller than the process and stricter than intuition.

| Signal | How to verify | Action if it fails |
|---|---|---|
| Covered spec | Test or described manual case | Return to spec |
| Sufficient context | Files and contracts cited | Reopen context step |
| Clean tests | Command recorded in PR | Fix before PR |
| Clean lint and types | CI or local command output | Fix before PR |
| No review blocker | Risk list reviewed | Ask for human review |
| Cited source | Link and access date | Remove or verify claim |
If all signals pass, the agent can open a PR with an objective description: problem, approach, commands run, risks and next steps. If any signal fails, do not turn failure into a footnote. Return to the loop, reduce scope or call a person.
FAQ about code agent harnesses
What is a code agent harness?
It is an operating structure that surrounds the agent with spec, context, allowed tools, tests and an exit rule. In 2025, 84% of Stack Overflow respondents used or planned to use AI in development (Stack Overflow, Developer Survey 2025 AI, accessed 2026-06-30), so the edge is verification.
Is MCP required for agentic coding?
No. MCP is useful when the agent needs external tools with a clear contract. The MCP documentation defines it as an open standard for connecting AI to external systems (Model Context Protocol, What is MCP?, accessed 2026-06-30). For simple local changes, tests and CI are enough.
Do subagents save tokens?
They can save context when they isolate exploration and return a short synthesis. Claude Code documentation says subagents run in their own context windows and help preserve context (Anthropic, Create custom subagents, accessed 2026-06-30). If they return long dumps, the benefit disappears.
Do Codex and Claude Code need the same harness?
The exact implementation varies by tool, but the principle is the same. Codex, Claude Code and similar agents need a spec, scope, tools, verification and review. When the agent runs commands and edits files, the harness becomes part of engineering process.
Sources consulted
- Stack Overflow, Developer Survey 2025 AI, accessed 2026-06-30, https://survey.stackoverflow.co/2025/ai
- Anthropic, Create custom subagents, accessed 2026-06-30, https://code.claude.com/docs/en/sub-agents
- Anthropic, Connect Claude Code to tools via MCP, accessed 2026-06-30, https://code.claude.com/docs/en/mcp
- Anthropic, Automate actions with hooks, accessed 2026-06-30, https://code.claude.com/docs/en/hooks-guide
- Model Context Protocol, What is MCP?, accessed 2026-06-30, https://modelcontextprotocol.io/docs/getting-started/intro
- OpenAI, Introducing Codex, accessed 2026-06-30, https://openai.com/index/introducing-codex/